


Tanto cuando era candidato como ahora, que es el presidente, Donald Trumpha dejado clara su intención de aplicar políticas agresivas hacia las personas musulmanas, refugiadas y migrantes en el marco de la seguridad nacional. En su primera semana en el cargo, Trump promulgó la prohibición de viajes, manifiestamente ilegal, que impide la entrada en Estados Unidos de todas las personas, refugiadas incluidas, procedentes de siete países de mayoría musulmana. Una segunda orden ejecutiva promulgada la misma semana, así como los memorandos de política que la acompañaron posteriormente, ampliaron las facultades de las agencias encargadas de aplicar la ley y de inmigración para aumentar la detención y expulsión de personas migrantes indocumentadas.
Aunque no sabemos lo que deparará el futuro, las declaraciones del presidente suscitan sin duda gran preocupación. Trump se ha negado de manera notoria a descartar la posibilidad de crear un “registro de musulmanes”, y ha manifestado su intención de expulsar rápidamente a entre dos y tres millones de personas migrantes indocumentadas.
Quienes están organizando la oposición a los planes de Trump dan por supuesto en gran medida que cualquier iniciativa de recopilación de datos en gran escala conllevará exactamente eso: una iniciativa de recopilación de datos en gran escala. Cientos de personas en Twitter se han comprometido a registrarse como musulmanes con la etiqueta #RegisterasMuslim en el caso de que el gobierno estadounidense implantara dicha política, entre ellas la ex secretaria de Estado Madeleine Albright.
Pero el registro solidario podría ser inútil, dado que lo que se viene llamando “registro de musulmanes” probablemente se parecería mucho más al discriminatorio Sistema de seguridad nacional de registro de entradas y salidas del territorio (National Security Entry-Exit Registration System, NSEERS), aplicado para citar para un “registro especial” a los hombres procedentes de 24 países de mayoría musulmana y de Corea del Norte durante la presidencia de Bush.
Pero tal vez un “registro de musulmanes” — o lista de objetivos para la expulsión, en realidad — tendría que conllevar necesariamente el registro.
En los últimos 10 años se ha producido un auge de los macrodatos. La propia magnitud de los datos sobre las personas, combinada con los avances en las técnicas de minería de datos, hace que cientos de empresas estadounidenses posean actualmente “superbases de datos” de cientos de millones de consumidores identificables individualmente.
Y no estamos hablando solamente de los Googles y Facebooks del mundo. Son empresas de las que probablemente no habrás oído hablar, aunque su actividad es conocerte. Cada vez que usas tu tarjeta de crédito, habilitas el wifi en tu teléfono móvil, lees noticias online, marcas una casilla de condiciones, autorizas a una aplicación el acceso a tus cuentas en redes sociales, respondes a una encuesta o haces una compra, es más que probable que haya una empresa — o varias — que compite por tus datos.
Si el presidente estadounidense quisiera efectivamente crear un registro de todas las personas musulmanes que residen en Estados Unidos; o supongamos que quisiera saber a cuántos hogares dirigirse como parte de una agresiva nueva política de inmigración centrada en la expulsión de migrantes indocumentados: ¿hasta qué punto le sería fácil reunir ese tipo de datos en 2017 sin tener que registrar formalmente a cada persona?
¿Es fácil comprar datos personales?
Los datos se compran y venden de muchas formas, y en esas transacciones participan mucho tipos de agentes. Esos dados van desde los de carácter demográfico a otros productos mucho más elaborados como predicciones y perfiles basados en hábitos de consumo o estimación de riesgos financieros. Antes de considerar las posibilidades técnicas y los riesgos que plantean para los derechos humanos algunas de las modernas técnicas de análisis de datos, merece la pena detenerse a pensar en los tipos de datos que ya hay disponibles de forma generalizada en Internet.
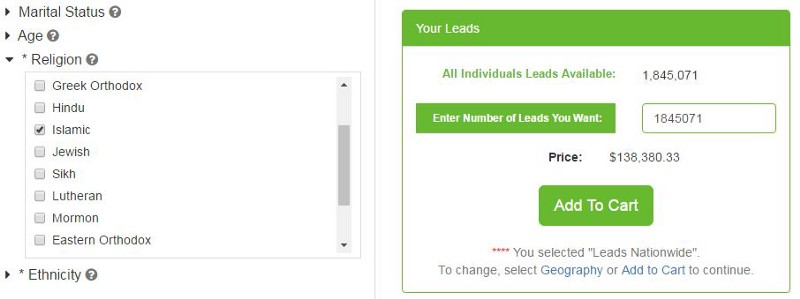
En sólo cinco clics en ExactData.com estaremos ante un presupuesto para descargar datos sobre 1.845.071 personas que figuran como musulmanas en Estados Unidos.
Por 138.380 dólares estadounidenses, el sitio web ofrece un archivo de base de datos que contiene más de 1,8 millones de nombres, domicilios, ciudades, estados y códigos postales. A tan sólo 7,5 centavos por persona.
ExactData.com presume de tener una base de datos total de 200 millones de contactos en Estados Unidos que se pueden filtrar mediante 450 categorías, como “religión” y “etnia”, así como mediante información personal como “ingresos familiares” y “marca del vehículo”.
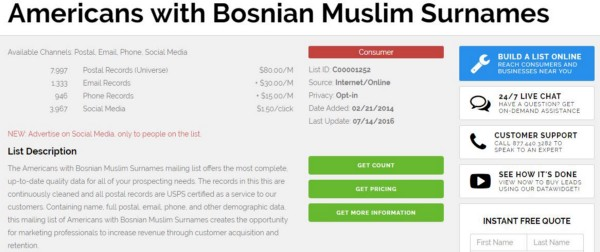
El sitio web también ofrece amablemente un abanico de listas de contactos preconfiguradas, como la de “estadounidenses con apellidos musulmanes bosnios” y una titulada “estadounidenses hispanos no asimilados”.
Los únicos datos que no se encuentran fácilmente en el sitio son los relativos a cómo se compilan las listas. Clicaran o no en una ocasión “OK” para dar su consentimiento a la recopilación inicial de estos datos, uno se pregunta cuántas de esas personas sabían que un día estos datos las incluirían en una de estas listas.
ExactData.com es uno de los cientos de empresas privadas de Estados Unidos dedicadas a acumular y vender datos personales. Conocidas comúnmente como “corredores de datos”, estas empresas venden una serie de servicios, desde “generación de contactos” y “análisis predictivos” a “verificaciones de antecedentes” e “inteligencia privada” (“¿Quiere saber más sobre su pareja?”, ofrece una empresa llamada Spokeo).
No todas las empresas hacen que sea tan fácil descargarse inmediatamente una lista, pero muchas venden esta información. Una búsqueda en Nextmark, una especie de repositorio de listas, da varias entradas para “musulmanes”, incluidas listas de otros corredores de datos como Sprint Data Solutions y E-Tech. Experian, mucho mayor y uno de los corredores de datos más grandes del mundo, ofrece “181 etnias detalladas” en su catálogo de listas, que incluye la categoría “islámico” junto a otras 11 religiones.
Y estos son sólo los datos que comercializan en línea. ¿Cuántos datos sobre nosotros pueden ver estas empresas?
Una empresa de análisis de datos accedió a darnos el número de “musulmanes” de su base de datos, siempre que no mencionáramos el nombre de la empresa. Nos dijeron que tenían datos de 3,7 millones de personas identificables individualmente, basados en datos de encuestas, información sobre conducta de consumo, datos de sondeos e información sobre la distribución geográfica de las religiones en Estados Unidos. La empresa creía tener una “certeza del 85%” sobre las personas de “etnia musulmana” (definidas como musulmanas practicantes o que se habían criado en la fe islámica).
La cifra de 3,7 millones es más del doble que la que ofrece ExactData.com y algo superior al cálculo del Pew Research Centre del número total de musulmanes en Estados Unidos en 2015.
Naturalmente, hay usos benignos de este tipo de datos. Una lista de donantes musulmanes de Sprint Data Solutions anuncia que “este archivo ha dado GRANDES resultados las para actividades de socorro en Oriente Medio”.
Sin embargo, es evidente que la acumulación de estas enormes cantidades de datos personales representa grandes riesgos y que hay muchos usos potencialmente peligrosos que se pueden dar a esta información. La Oficina del Censo estadounidense no ha hecho preguntas sobre religión desde la década de 1950; se retiraron del censo precisamente porque se consideraba información privada y delicada.
Te presentamos el mercado que comercia contigo
La industria de los corredores de datos y de análisis de consumo ha evolucionado con el tiempo en respuesta a la demanda del mercado de datos agregados y calificaciones predictivas basadas en esos datos. Los macrodatos son esenciales cuando se estratifican y combinan volúmenes considerables de datos. Este tipo de análisis reúne en un solo lugar toda o gran parte de la amplia información que existe sobre los consumidores. Esto puede incluir información de las redes sociales, el historial de navegación en Internet, el historial financiero o de compras, el laboral, la seguridad social, los antecedentes penales y judiciales, los informes crediticios, los números de teléfono fijos y móviles, domicilios y registros de conducción, entre otras muchas clases de datos.
Los titanes de la industria — empresas globales como Acxiom, Experian y Palantir — no son precisamente nombres conocidos en Estados Unidos… pero su trabajo es conocer íntimamente cada hogar estadounidense. Acxiom dice que “recopila y mantiene un almacén de información sobre consumo que cubre casi todos los hogares de Estados Unidos”. Experian es una conocida agencia de crédito, pero también proporciona servicios de comercialización “utilizando su base de datos de 235 millones de consumidores estadounidenses”.
Esas bases de datos plantean numerosos riesgos de que se facilite la discriminación contra las personas. Pero también se plantean otros problemas derivados del hecho de que esas bases de datos no son perfectas.
“Toda la industria de datos se basa en los márgenes de error”, nos dijo un alto cargo con años de experiencia en el sector de los datos comerciales (con la condición de preservar su anonimato). “Casar diversos conjuntos de datos con personas concretas es una ciencia imperfecta y es fácil cometer errores. Éstos se concentran en etnias que tienen una mayor proporción de nombres en común: hispanos y latinos primero, musulmanes después”.
Al menos algunos corredores de datos con los que contactamos no parecían demasiado preocupados por las posibles repercusiones de estos “márgenes de error”. Escribimos a tres corredores que proporcionan presupuestos por correo electrónico para ver si ofrecerían vender una lista de “inmigrantes indocumentados” en el estado de California. Nos respondieron dos. Uno nos dijo que aunque, lamentablemente, “no tenemos forma de conocer su condición jurídica exacta, podemos crear una lista que sería lo más próximo que podrían obtener de algo similar; podemos identificar a personas de diferentes países de origen en función de su etnia y/o raza, junto con su preferencia de primera lengua”.
Otra empresa respondió en una línea que podrían proporcionar una “lista de inmigrantes indocumentados” en California, y que creían que tenían “más de un millón de fichas”. Cuando volvimos a escribirles preguntando la precisión que creían que tendría la lista, el gerente de la empresa respondió:
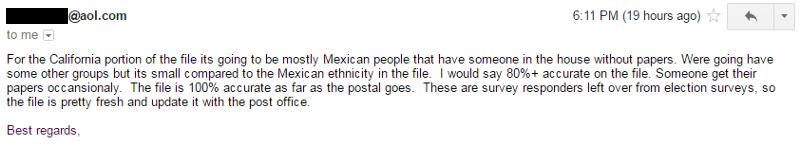
Para la parte del archivo relativa a California, serán en su mayoría personas mexicanas que conviven con alguien que carece de documentos. Vamos a tener algunos grupos más, pero es pequeño en comparación con la etnia mexicana del archivo. Yo diría que el archivo tiene una exactitud de más del 80%. Algunas personas consiguen en ocasiones su documentación. El archivo es 100% preciso en lo que se refiere a la dirección postal. Son personas encuestadas que quedaron de encuestas sobre las elecciones, por lo que el archivo es bastante nuevo y se puede actualizar con las oficinas de Correos.
No cabe duda de que el hecho de que algunas empresas estén dispuestas a vender listas de “inmigrantes indocumentados” es problemático en un contexto de xenofobia y crímenes de odio crecientes en Estados Unidos. Pero también hay preguntas sobre qué pasa cuando las agencias encargadas de la aplicación de la ley o de inmigración del gobierno estadounidense acceden a estos datos y actúan en función de ellos.
¿Qué dice la ley?
Aparentemente, los corredores de datos operan en una laguna legal. Las protecciones a la privacidad contenidas en las leyes parlamentarias y en la Constitución no les son aplicables en general, especialmente en lo que se refiere a su uso por agencias encargadas de hacer cumplir la ley.
Cuando preguntamos a otro alto cargo de la industria de datos (que también habló con nosotros con la condición de preservar su anonimato) a qué normas estaban sometidos, la respuesta fue: “Esto es un poco como el salvaje Oeste.”
Las leyes que sí se aplican suelen estar llenas de excepciones. La Ley sobre Privacidad de 1974, por ejemplo, establece normas para la recopilación, uso y gestión de datos personales por parte del gobierno, pero sólo se aplica a las agencias federales (no a las estatales ni a las locales), y sólo cuando estas agencias establecen su propio “sistema de registros”, y no cuando se limitan a acceder a los registros que son propiedad del sector privado o que este se encarga de alojar. Además, esta ley sólo se aplica a los ciudadanos y ciudadanas estadounidenses y a residentes permanentes, y la política de Seguridad Nacional que había ampliado las protecciones de la Ley sobre Privacidad a algunos datos gubernamentales sobre otros grupos de no ciudadanos fue revocada la semana pasada en previsión del aumento de la aplicación de las normas sobre inmigración.
Esta laguna legal es criticada desde hace muchos años, y los problemas que plantea respecto de la privacidad han desembocado en expresiones de preocupación de la Casa Blanca, durante la presidencia de Obama. En 2015, cuatro senadores demócratas llegaron al punto de presentar, sin mucho éxito, un proyecto de ley sobre Rendición de Cuentas y Transparencia de Corredores de Datos. El senador Ed Markey (demócrata por Massachusetts), que presentó el proyecto legislativo, dijo: “Necesitamos arrojar luz sobre esta industria de recogida subrepticia de datos ‘en la sombra’ que ha acumulado expedientes encubiertos de cientos de millones de estadounidenses.”
Los debates en curso sobre la legalidad y la constitucionalidad de programas de vigilancia del gobierno como los que dirige la NSA podrían llevarnos razonablemente a suponer que la Constitución estadounidense impone límites a la adquisición de datos de corredores comerciales por las agencias gubernamentales. En la mayoría de los casos no es así.
Según la “doctrina de terceros”, establecida hace décadas por la Corte Suprema estadounidense, las personas no tienen una expectativa legítima de privacidad respecto de los datos facilitados voluntariamente a terceros. En otras palabras, una vez que se recopilan legalmente datos sobre alguien para un determinado fin, estos datos pueden ser reutilizados o revendidos reutilizarse por otros para casi cualquier otro fin. Por tanto, las agencias gubernamentales pueden eludir las leyes concebidas para impedirles que recopilen datos personales simplemente comprando (o pidiendo) esos datos a empresas que no están sometidas a estas restricciones.
“Es un secreto razonablemente conocido que las agencias encargadas de la aplicación de la ley y de inteligencia estadounidenses consiguen archivos de datos de este tipo de empresas para entender a la población estadounidense”, dijo el primer alto cargo de la industria de datos con el que hablamos.
Como botón de muestra, la NSA u otras agencias que realizan labores de vigilancia en virtud de la orden ejecutiva 12.333 no deberían reunir deliberadamente información sobre “personas estadounidenses” ni compartir esa información con agencias encargadas de la aplicación de la ley del país, pero las numerosas excepciones de este principio significan que, en realidad, se recopilan y comparten muchísimos datos sobre los estadounidenses. Una de estas excepciones es la relativa a la información “disponible públicamente por suscripción o compra”. En otras palabras, si la NSA puede comprar información sobre los estadounidenses a corredores de datos, puede compartirla con el FBI y otras agencias encargadas de hacer cumplir la ley estadounidenses.
Las relaciones entre los corredores privados de datos y el gobierno son antiguas y arraigadas, y algunos corredores tienen miles de clientes entre las agencias encargadas de la aplicación de la ley. Como dijo el vicepresidente de ChoicePoint (adquirida posteriormente por el RELX Group) en 2005, “actuamos como una agencia de inteligencia, recopilando datos, haciendo análisis.”
Paul Ohm, catedrático de Derecho de Georgetown, ha escrito: “Nuestra imagen mental del agente del FBI que hace labores de vigilancia con auriculares en una furgoneta blanca estacionada junto al bordillo, pone pinzas en cables de teléfono y trabaja con un científico de bata blanca del FBI será sustituida en breve por la de un agente sentado en su despacho que pulsa la tecla de actualizar del navegador y lee el último volcado de archivos de registros enviado por la industria privada.”
Estas alianzas ya son enormemente preocupantes para los derechos humanos, pero ¿qué pasará mientras acelera el sector privado de las tecnologías de minería de datos?
Cuando los datos se vuelven inteligentes: ¿qué podrían contarle los análisis de macrodatos al gobierno de Trump?
A finales de enero, un artículo de Motherboard describía a una empresa relativamente pequeña de Londres llamada Cambridge Analytica, con la que el entonces candidato Donald Trump tenía un contrato para ayudarlo en su campaña electoral. El estratega jefe de Trump, Steve Bannon, ha pertenecido hasta hace poco al consejo de administración de Cambridge Analytica, empresa respaldada económicamente por el inversor multimillonario Robert Mercer, cuya hija formó parte del equipo de transición de Trump.

El sitio web de Cambridge Analytica dice que tienen “4.000 o 5.000 puntos de datos sobre cada persona” y una “base de datos nacional de más de 220 millones de estadounidenses”. Un vídeo de su canal de YouTube, titulado “The Future of Political Campaigns” (“El futuro de las campañas políticas”), describe lo que hacen:
“La mayoría de las agencias usan datos demográficos como el género y el estado civil, geográficos como códigos postales y psicográficos como gastos de hábitos de vida para ayudarte a encontrar audiencias objetivo. Pero Cambridge Analytica es diferente. Recopilamos, casamos y organizamos tus datos con los nuestros […] añadimos una capa extra de datos sobre personalidad para llegar a un nivel individual. Y agrupamos a las personas con rasgos de carácter comunes. Eso hace que nuestras conexiones sean más profundas e inteligentes, y nos permite identificar perspectivas precisas para que puedas enviar el mensaje adecuado.”
El consejero delegado de la empresa, Alexander Nix, declaró en una entrevista radiofónica para la BBC que Cambridge Analytica usaba macrodatos para “agregar todos los puntos de datos […] todos los que se puedan obtener […] datos de redes sociales, transacciones, consumo y todos los demás tipos de datos van al crisol”. La empresa vincula después estos datos con sus propios modelos predictivos de personalidad, asignando a cada persona un tipo de personalidad — como “extrovertida” o “impulsiva” — con un algoritmo desarrollado en Facebook.
Esto es un salto hacia adelante respecto de los archivos basados en listas que venden muchos corredores de datos. Los modelos anteriores hacían predicciones sobre quién es “musulmán” con parámetros bastante poco precisos, por ejemplo, casando apellidos asociados a musulmanes con lugares geográficos conocidos por tener una gran proporción de personas de comunidades étnicas o nacionales específicas. Pero con los avances en la inteligencia artificial y unos conjuntos de datos cada vez más integrados, es posible hacer predicciones muy precisas sobre atributos como la religión, y en potencia, incluso sobre el estatuto jurídico de una persona.
El profesor Paul Ohm nos dijo que esto se debe en parte a que “los daños a la privacidad pueden caer en cascada de formas inesperadas”, es decir, que incluso datos que no parecen exclusivos de una persona pueden revelar mucha información personal. En su texto, cita numerosos ejemplos de cosas que los investigadores creen que pueden revelar una identidad única, como preferencias de películas o búsquedas en Internet, y afirma que la capacidad para inferir una identidad única a partir de datos aparentemente anónimos amenaza con menoscabar gravemente gran parte de la legislación estadounidense sobre privacidad, que suele tratar el anonimato de los datos como protección frente a los daños a la privacidad.
Michal Kosinski, investigador de la Universidad de Stanford y el primero en anticipar el tipo de modelo predictivo de personalidad que ya afirma usar Cambridge Analytica, explicó cómo se pueden hacer predicciones sobre personas basándose en su huella digital:
“No estoy seguro de la precisión del modelo de Cambridge Analytica, pero haciendo yo mismo este tipo de investigación puedo decir que se puede desarrollar fácilmente un modelo que predice la filiación religiosa basándose en actualizaciones de estado, los ‘me gusta’ de Facebook y otra información de redes sociales. Yo podría hacerlo sólo con mi ordenador portátil. Y como académico me limito a los datos a los que tengo acceso. Si se dispone de todo un equipo de científicos de datos y se pueden comprar datos a empresas, es muy fácil imaginar que suceda esto: las empresas tendrían más datos, más datos íntimos, y más potencia computacional”.
En otras palabras, no sólo hemos de tener en cuenta qué tipo de información delicada está codificada explícitamente en los datos sobre nosotros, como el país de origen, la etnia y el número de seguridad social, sino también las inferencias delicadas que se pueden decodificar o deducir a partir de nuestros datos. Las técnicas modernas de aprendizaje mecánico pueden crear percepciones sorprendentes a partir de datos dispares, revelando rasgos íntimos ocultos hasta ese momento — religión, estado civil, orientación sexual, afiliación política — sobre los que antes teníamos al menos cierto margen para decidir mantenerlos en privado. Kosinski explica:
“Cuando hablo de la huella digital, la gente suele pensar en ella así: si visitas habitualmente un sitio web musulmán, podríamos adivinar que eres musulmán. Pero no estoy hablando de eso. Hoy día podemos ir a tu lista de reproducción de Spotify y hacer una predicción muy precisa de que eres musulmán basada en las canciones que escuchas. No hace falta que tengas relaciones online con un partido político para que el algoritmo infiera si eres republicano o demócrata. Al desarrollar un algoritmo con un conjunto de datos lo suficientemente grande, podemos hacer inferencias a partir de los patrones de los ‘me gusta’ de tu Facebook.”
La inteligencia artificial ha liberado un gigantesco potencial nuevo para las empresas que tienen las llaves de nuestros datos. Y esa es una de las razones por las que la industria crece con tanta rapidez. Las empresas compiten para adquirir y conectar el universo de datos siempre en expansión sobre cada uno de nosotros. Una tercera fuente de la industria de datos y la comercialización con la que hablamos (que también desea mantener el anonimato) lo explicó así: cada vez que una empresa vincula dos esferas de información sobre ti (por ejemplo, los datos asociados a tu dirección de correo electrónico y tu actividad en YouTube) “es un importante impulso para la inteligencia artificial. Es como cuando Neo instala el programa de Kung Fu en Matrix”.
Ahora que los medios informan de nuevos posibles contratos entre Cambridge Analytica (y su empresa matriz, SCL Group) y la Casa Blanca, la ausencia de regulación o de directrices éticas sobre cómo se pueden recopilar y usar los datos personales es alarmante.
Preguntamos a una empresa de análisis de datos con la que hablamos si podrían teóricamente crear con sus datos un modelo para detectar a personas migrantes en situación irregular. La empresa respondió que nunca firmaría un contrato de este tipo, pero pensaba que “el concepto general es posible”. También dijo que cualquier operación de este tipo daría “falsos positivos”; en otras palabras, residentes legales y ciudadanos y ciudadanas que terminarían en la lista por error.
¿Usaría el gobierno de Trump conjuntos comerciales de datos para llevar a cabo un “mapeo de población” que sirviera de base a la política sobre inmigración? Quizá. Pero con independencia de los conocimientos que puedan ofrecer empresas comerciales, hay algo seguro: esos conocimientos empezarían a ser más detallados cuando se integren con las bases de datos sobre inmigración y aplicación de la ley del propio gobierno.
Los corredores de datos y las empresas de análisis de datos también tienen responsabilidades en materia de derechos humanos y sobre la ética en el manejo de datos
La industria tecnológica en general criticado la prohibición de viajar de Trump. La primera semana de febrero, 97 empresas — incluidas Google, Facebook, Apple y Microsoft — se unieron para presentar un informe de amicus curiae en apoyo a una demanda contra las órdenes sobre inmigración de Trump.
Además, casi 3.000 profesionales de la industria tecnológica han firmado un compromiso para — entre otras cosas — negarse a colaborar en la creación de bases de datos discriminatorias. Entre ellas hay personas que trabajan para seis de las empresas de correduría de datos que analizó Amnistía para esta investigación.
Según los medios de comunicación, algunos corredores de datos, como Acxiom, Recorded Future y CoreLogic, han declarado expresamente que no contribuirían en la creación de un registro de musulmanes.
Pero la industria de la correduría y de los análisis de datos es un ecosistema enorme de flujos de datos, y únicamente haría falta la colaboración de una sola empresa pequeña o mediana para que las autoridades obtengan acceso a datos extraordinariamente detallados sobre personas musulmanas o migrantes en Estados Unidos.
Y a tenor de todo lo que sabemos, Trump y la gente que lo rodea ya se llevan muy bien con algunas de ellas. Además de la relación del gobierno de Trump con Cambridge Analyica, Peter Thiel, consejero delegado de Palantir, formó parte también del equipo de transición del presidente. El consejero delegado de Palantir ha declarado públicamente que no se ha pedido a la empresa que cree un registro de musulmanes y que “no lo haría si se le pidiera”. Pero la empresa tiene contratos multimillonarios activos con la Agencia de Inmigración y Aduanas estadounidense, que incluyen la gestión y el mantenimiento de un sistema para cotejar y analizar un amplio banco de información personal basada no solamente en expedientes del gobierno, sino también en datos disponibles comercialmente y de fuentes abiertas.
Aunque quizá no podamos predecir qué va a pasar, es evidente que los riesgos para los derechos humanos son enormes. Los corredores de datos y las empresas de análisis de datos, como todas las empresas, tienen la responsabilidad de respetar los derechos humanos, lo que significa que deben asegurarse de que no provocan abusos contra los derechos humanos ni contribuyen a ellos.
Esa es exactamente la razón por la que hoy, Amnistía, junto con 16, está escribiendo a cerca de 50 corredores de datos en Estados Unidos, que constituyen una muestra representativa del mercado,
pidiéndoles que hagan públicas las medidas que adoptan para garantizar que no violan la ética en materia de manejo de datos ni contribuyen a que se cometan abusos contra los derechos humanos y que se comprometan a no permitir que las autoridades usen sus datos o servicios de modo que se violen derechos humanos, especialmente los derechos de las personas musulmanas y migrantes, claramente en peligro.
Nos hemos puesto en contacto con una serie de empresas mencionadas en el informe solicitándoles sus comentarios. La única respuesta que hemos recibido antes de la publicación fue de un portavoz de SCL / Cambridge Analytica, quien dijo:
“Estamos perplejos ante el hecho de que el autor haya optado por incluir a nuestra empresa en un artículo sobre un asunto ajeno a ella. También lamentamos que el artículo presente una imagen distorsionada de la empresa”.