


We do not know what the future holds, but the President’s statements certainly give cause for serious concern. Trump has notoriously refused to rule out the possibility of a “Muslim registry”, and has stated his intention to quickly deport between 2 and 3 million undocumented immigrants.
Those who’ve mounted opposition to Trump’s plans have largely taken for granted that any large-scale data collection effort would involve exactly that: a large-scale data collection effort. Hundreds on Twitter pledged to #RegisterasMuslim should the US government mandate such a policy, among them former Secretary of State Madeleine Albright.
But solidarity registration could be futile given that a so-called “Muslim register” would much more likely resemble the discriminatory National Security Entry-Exit Registration System (NSEERS) program, which saw men from 24 Muslim-majority countries and North Korea summoned for “Special Registration” under former President Bush.
But perhaps a “Muslim registry” — or list of deportation targets, for that matter — would not necessarily have to involve registration at all.
The past 10 years have witnessed a boom in big data. The sheer scale of data about people, combined with advances in data mining techniques, mean that hundreds of US companies now possess “super databases” of hundreds of millions of individually-identifiable consumers.
And we’re not talking only about the Googles and Facebooks of the world. These are companies you probably haven’t heard of — although it’s their business to know you. Every time you use your credit or debit card, enable wifi on your mobile, read the news online, tick a Terms and Conditions box, authorize an app to access your social media accounts, contribute to a survey, or make a purchase, the chances are there is a company out there — or several — vying for your data.
If the US President did indeed want to build a register of every Muslim living in the United States — or let’s say he wanted to know which households to target as part of an aggressive new immigration policy focused on deportation of undocumented migrants — just how easy would it be for him to gather that kind of data in 2017, without having to formally register a single person?
Just how easy is it to buy personal data?
Data is purchased and sold in many forms, by many types of actors. These range from demographic data to more sophisticated products such as predictions and profiles based on spending habits or perceived financial risk. Before considering the technical possibilities and the risks to human rights posed by some of the modern data analytics techniques, it is worth pausing to consider the types of data that are already widely available online.
It takes just five clicks on ExactData.com and we are staring at a quote to download data on 1,845,071 people listed as Muslim in the United States.
For the price of $138,380, the website offers a database file containing more than 1.8 million individual names, addresses, cities, states and ZIP codes. Just 7.5 cents per person.
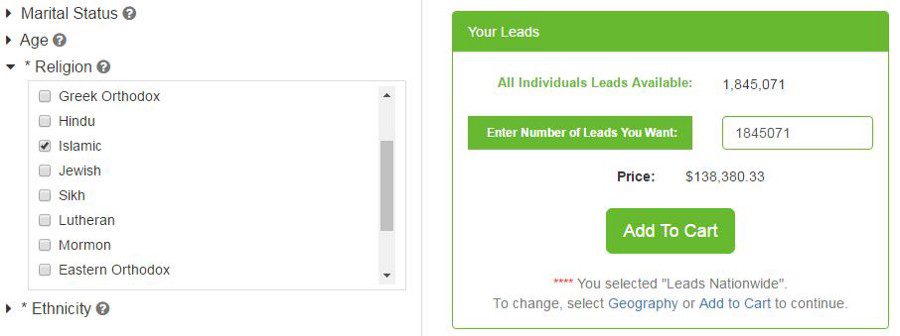
ExactData.com boasts a total database of 200 million US contacts, which can be filtered by 450 terms. These include categories such as “Religion” and “Ethnicity”, as well as personal information such as “Household Income” and “Vehicle Make”.
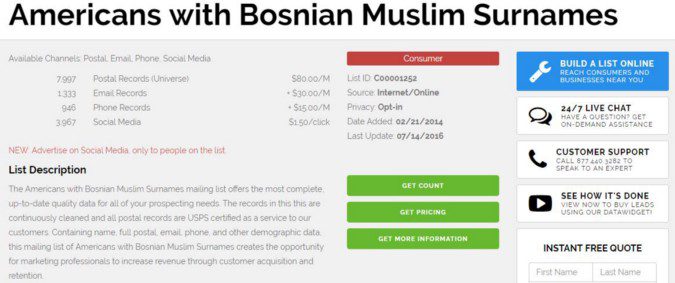
The website also helpfully offers a range of pre-made contact lists. Among them are lists such as “Americans with Bosnian Muslim Surnames” and one called “Unassimilated Hispanic Americans”.
The only data not readily available on the site is information about how the lists are compiled. Whether or not people once clicked “OK” to consent to the initial collection of this data, one wonders how many knew how that data would one day land them on one of these lists.
ExactData.com is one of hundreds of private companies in the US whose business is amassing and selling people´s personal data. Frequently referred to as ‘data brokers’, these companies sell a range of services, from ‘lead generation’ and ‘predictive analytics’ to “background checks” and “private intelligence” (“looking to learn more about your date?”, offers a company called Spokeo).
Not every company makes it quite so easy to download a list right away. But many sell this information. A search on Nextmark, a kind of clearing house for lists, contains several entries for “Muslim”, including lists from other data brokers such as Sprint Data Solutions and E-Tech. The much larger Experian, one of the biggest global data brokers offers “181 detailed ethnicities” in its list catalogue, including the category “Islamic”, alongside 11 other religions.
And this is only the data they market online. Just how much data about us can these companies see?
One data analytics company agreed to provide us with a count for “Muslims” in their database, provided we agreed not to name the company. They told us they had data for 3.7m individually identifiable individuals, modeled from survey data, consumer behavior information, polling data, and information about the geographic distributions of religions in the United States. The company believed it to be “85% accurate” on people of “Muslim ethnicity” (defined as either a practicing Muslim or someone who grew up in the Islamic faith).
3.7 million is more than double the number offered by ExactData.com and slightly above the Pew Research Centre´s estimate of the total number of Muslims in the USA in 2015.
Of course, there are benign uses for this kind of data. A Muslim Donors list from Sprint Data Solutions advertises that “this file has turned GREAT results for middle east relief efforts”.
However, it’s clear that the amassing of such large amounts of personal data poses serious risks and that there are many potentially dangerous uses to which this information could be put. The U.S. Census Bureau has not asked questions about religion since the 1950s; it was dropped from the census precisely because it was considered to be private and sensitive information.
Introducing the market that trades in you
The data broker and consumer analytics industry has evolved over time in response to a market demand for big data and predictive scores and analysis based on that data. Big data is essential where substantial volumes of data are layered and blended. This kind of analysis brings together all or much of the far-flung information that exists about consumers in one place. This can include social media information, internet browsing history, financial/purchase history, employment history, social security, criminal records, court records, credit reports, home and cell phone numbers, addresses and driving records, among many other kinds of data.
The titans of the industry — global companies like Acxiom, Experian and Palantir — are not exactly household names in the US. But their job is to know each US household intimately. Acxiom says it “collects and maintains a storehouse of consumer information covering nearly every household in the US”. Experian is a well-known credit bureau, but it also provides marketing services “by tapping its database of 235 million US consumers”.
Such databases pose numerous risks of facilitating discrimination against people. But still other problems arise due to the fact that these databases are not perfect.
“The whole data industry relies on margins of error”, a senior individual with years of experience in the commercial data space told us (on the condition of anonymity). “Matching various datasets to specific individuals is an imperfect science and it’s easy to get it wrong. These errors are concentrated on ethnicities who have a higher proportion of names in common — Hispanic and Latinos first, Muslims second”.
At least some data brokers we approached didn’t seem too concerned about the potential repercussions of these “margins of error”. We wrote to three brokers who provide quotes over email to see if they would offer to sell a list of “undocumented immigrants” in the State of California. Two got back to us. One told us that while there was unfortunately “no way for us to know their exact status, we can model a list that would be the closest you could get to something like this — we can target individuals from different countries of origin according to their ethnicity and/or race, along with their first language preference”.
Another company responded in one line that they could provide an “undocumented immigrants list” for California, and that they believed they had “over a million records”. When we wrote back asking how accurate they thought the list would be, the company manager replied:
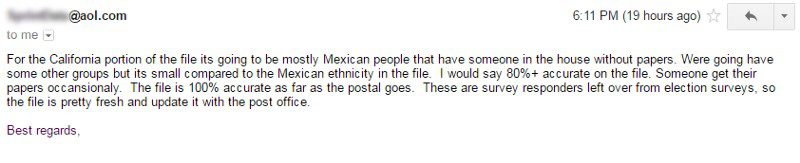
The fact that some companies are prepared to sell lists of “undocumented immigrants” is certainly problematic in a context of rising xenophobia and hate crime in the US. But there are also questions about what happens when law enforcement or immigration agencies of the US government access, and act upon, such data.
What does the law say?
Data brokers appear to fall into a legal gap. The privacy protections afforded by statutes or the Constitution generally do not apply to them, especially where their use by law enforcement agencies is concerned.
When we asked another senior individual in the data industry (who also spoke to us on the condition of anonymity) what regulation they were subject to, the response was: “It’s a little bit of the Wild West over here.”
Those laws that do apply are generally riddled with exceptions. The Privacy Act of 1974, for example, establishes rules for government collection, use and management of personal data, but it applies only to federal agencies (not state or local), and only when those agencies establish their own “system of records,” not when they simply access records held or created by private industry. The act also only applies to US citizens and permanent residents, and Homeland Security policy that had extended Privacy Act protections to some government data on other groups of non-citizens was revoked last week in anticipation of ramped up immigration enforcement.
This legal gap has been the subject of criticism for many years, and the privacy concerns it raises have even led to expressions of concern from the White House, under President Obama. In 2015, four Senate Democrats got as far as introducing a new Data Broker Accountability and Transparency bill, without much success. Senator Ed Markey (D-Mass.), who introduced the bill, said “We need to shed light on this ‘shadow’ industry of surreptitious data collection that has amassed covert dossiers on hundreds of millions of Americans.”
Ongoing debates about the legality and constitutionality of government surveillance programs such as those run by the NSA might reasonably lead one to assume that the US Constitution places limits on the acquisition by government agencies of data from commercial brokers. In most cases it does not.
Under the “third-party doctrine,” established decades ago by the US Supreme Court, people have no legitimate expectation of privacy for data voluntarily handed over to third parties. In other words, once data is legally collected about you for one purpose, it can be reused or resold by others for almost any other purpose. Government agencies can thus do an end run around laws designed to restrain them from collecting personal data about people by simply buying (or demanding) that data from companies that are subject to no such restraints.
“It is a reasonably open secret that US law enforcement and intelligence agencies procure data files from these kinds of companies to understand the American population”, said the first senior data industry source we spoke to.
As but one example, the NSA or other agencies conducting surveillance under Executive Order 12,333 are not supposed to intentionally gather information on “US persons”, or share that information with domestic law enforcement. But the many exceptions to this principle mean that in fact, a great deal is collected and shared about Americans. One such exception is for information “available to the public by subscription or purchase.” In other words, if the NSA can buy Americans’ information from data brokers, they can share it with the FBI, and other domestic law enforcement agencies.
Relationships between private data brokers and the government are longstanding and well established, and some data brokers have thousands of law enforcement clients. As the vice-president of ChoicePoint (later acquired by RELX Group) put it in 2005, “We do act as an intelligence agency, gathering data, applying analytics.”
Georgetown Law Professor Paul Ohm has written, “Our mental image of the FBI agent conducting surveillance, wearing headphones in a white van parked on the curb, clipping alligator clips to telephone wires, and working with a white-coated FBI scientist will soon be replaced by an agent sitting in his office, hitting the refresh button on his web browser, and reading the latest log file dump sent from private industry.”
Such partnerships are already deeply concerning for human rights but what will happen as private sector data mining technologies accelerate?
When data gets intelligent: what could big data analytics tell Trump’s administration?
In late January, a Motherboard article profiled a relatively small London-based company called Cambridge Analytica, which then-candidate Donald Trump had contracted to help his election campaign. Trump’s Chief Strategist, Steve Bannon, until recently sat on Cambridge Analytica’s Board and the company is financially backed by billionaire investor Robert Mercer, whose daughter sat on Trump’s Transition Team.

Cambridge Analytica’s website says they have “4 or 5 thousand data points on every individual” and a “national database of over 220 million Americans”. A video on their YouTube channel, called “The Future of Political Campaigns”, describes what they do:
“Most agencies use demographics like gender and marital status, geographics like zip codes, and psychographics like lifestyle spending to help you find target audiences. But Cambridge Analytica is different. We collect, match and organize your data with our data… we add an extra layer of personality data to get down to an individual level. And group people with common character traits. It makes our connections deeper and smarter and lets us pinpoint precise prospects so you can send the right message.”
The company’s CEO, Alexander Nix, stated in a BBC radio interview that Cambridge Analytica use big data to “aggregate all data points… as many as you can get your hands on…Social media data, transaction, consumer and every other sort of data goes into the melting pot”. The company then links this data to their own predictive personality models, assigning each individual a personality type — such as extroverted, or impulsive — based on a Facebook-trained algorithm.
This is a leap forward from the list-based files sold by many data brokers. The earlier models made predictions about who is “Muslim” using fairly blunt metrics. For example, matching surnames associated with Muslims to geographies that were known to have a high proportion of people from specific ethnic or national communities. But with developments in machine learning, and more and more integrated datasets, it’s possible to make highly accurate predictions about attributes like religion, and potentially even legal status.
Professor Paul Ohm told us that this in part because “privacy harms can cascade in unexpected ways.” He meant that even data that does not appear unique to you can reveal a great deal of personal information. In his writing, he has cited numerous examples of things that researchers believe can reveal a unique identity, including movie preferences or internet search queries, and argued that the ability to infer unique identity from seemingly anonymous data threatens to seriously undermine much privacy legislation in the US, which often treats anonymization of data as protection against privacy harms.
Michal Kosinski, a Stanford University researcher who first advanced the kind of predictive personality modelling that Cambridge Analytica now claim to use, explained how one can make predictions about people based on their digital footprint:
“I am not sure how accurate Cambridge Analytica’s model is, but running this kind of research myself I can say that you can easily train a model that predicts religious affiliation based on status updates, Facebook likes and other social media information. I could do it with only my laptop. And as an academic I am limited in what data I can access. If you have a whole team of data scientists and can purchase data from companies, it’s very easy to imagine this happening — they’d have more data — more intimate data — and more computational power”.
In other words, we don´t just have to consider what kind of sensitive information is encoded explicitly in data about us — country of origin, ethnicity, social security number. We also have to consider what sensitive inferences can be decoded, or infered,from the data about us. Modern machine learning techniques can create surprising insights into disparate data, unveiling heretofore hidden intimate traits — religion, legal status, sexual orientation, political affiliation — that in the past we at least had some degree of choice about keeping private. Kosinski explains:
“When I talk about digital footprint people usually think of it like this: if you regularly visit a Muslim website, we might guess that you are Muslim. But that is not what I am talking about. Nowadays we can go to your Spotify playlist and make a highly accurate prediction that you’re Muslim based on which songs you listen to. You don’t have to have online associations with a political party for the algorithm to infer if you are a Republican or Democrat. By training an algorithm on a large enough dataset, we can tell from the patterns in your Facebook likes.”
Machine learning has unlocked huge new potential for the companies that hold the keys to our data. Which is one of the reasons the industry is growing so fast. Companies are racing to acquire and connect an ever expanding universe of data about each of us. A third source we spoke to in the data and marketing industry (who also wishes to remain anonymous) put it like this: each time a company links two spheres of information about you (e.g. the data associated with your email address and data associated with your YouTube activity) “it’s a shot in the machine learning arm. It’s like when Neo installs the Kung Fu programme in the Matrix”.
With the media reporting potential new contracts between Cambridge Analytica (and its parent company, SCL Group) and the White House, the lack of regulation or ethical guidelines about how personal data could be collected and used is alarming.
We asked a data and analytics company we spoke to if they could theoretically build a model to detect irregular migrants with their data. The company responded that they would never take a contract like that, but considered “the general concept to be possible”. They also said that any such exercise would result in “false positives” — in other words, legal residents and citizens who would mistakenly end up on the list.
Would the Trump administration use commercial datasets to carry out “population mapping” in order to inform immigration policy? Perhaps. But whatever insights could be offered up by commercial companies, one thing is certain: the insights would start to get a lot more granular when integrated with the government’s own immigration and law enforcement databases.
Analytics Companies and Data brokers have human rights and data ethics responsibilities, too
The tech industry has generally voiced criticism of Trump’s travel ban. In the first week of February, 97 companies — including Google, Facebook, Apple and Microsoft — joined forces by filing an amicus in support of a lawsuit against Trump’s immigration orders.
Nearly 3,000 tech professionals have also signed a pledge to — among other things — refuse to cooperate in building discriminatory databases. Among them are employees from six of the data broker companies Amnesty reviewed for this investigation.
According to media reports, some data brokers, including Acxiom, Recorded Future, and CoreLogic, have explicitly said they would not assist in building a Muslim registry.
But the analytics and data broker industry is a large ecosystem of data flows, and it would only take cooperation from a single small to medium company for the authorities to gain access to extraordinarily granular detail about Muslims or immigrants in the US.
And from everything we know, Trump and people around him are already friendly with a few. In addition to Trump administration’s relationship with Cambridge Analytica, Peter Thiel, a Board member at Palantir, was also part of the President’s Transition team. Mr. Thiel has publicly stated that the company has not been asked to build a Muslim registry, and “would not do so if asked”. But the company has active multimillion dollar contracts with the US Immigration, Customs and Enforcement Agency — including to operate and maintain a system for collating and analysing a vast bank of personal information drawn not only from government records, but also commercially available and open source data.
While we may not be able to predict what will happen, it is clear that the risks to human rights are enormous. Data brokers and data analytic companies — like all businesses — have a responsibility to respect human rights, which means making sure they don’t cause or contribute to human rights abuses.
This is exactly why today, Amnesty, along with 16 organizations, are sending letters to nearly 50 data broker and analytics companies in the United States, representing a cross-section of the market.
We are calling on them to make public what steps they take to ensure they don’t violate data ethics or contribute to human rights abuses and to take a pledge not to allow their data or services to be used by the authorities in ways that violate human rights, especially those of Muslims or migrants, whose rights are clearly under threat.
We approached a number of the companies named in the report for comments. The only response we received before publication was from a spokesperson for SCL/Cambridge Analytica, who said:
“We are puzzled as to why the author has chosen to include the company in an article on a matter that is unrelated to the company. We also regret that the article misrepresents the company.”